Basics
Content Category: Sentiment
Open:FactSet Page: Click here
Setup a Demo and Access Today: sales@factset.com
Alexandria's Transcript Text Analytics transforms unstructured text from company transcripts into actionable insights. Alexandria applies proprietary algorithms to company transcripts including earnings, investor, and public company calls to determine the sentiment and topic of each portion of text. These algorithms are trained by buy-side research analysts to replicate their own analysis, which yields more accurate and consistent classifications across a deep history of company transcripts. Each transcript is parsed into many sections of structured data that offer insight on what was said in that section, including the topic, sentiment, speaker, and more.
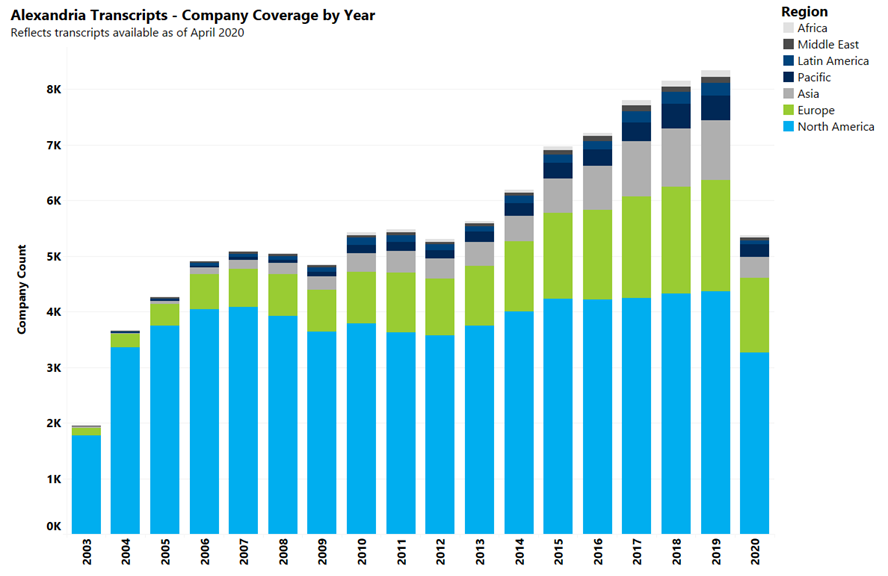
This product offers sentiment analysis of over 430,000 transcripts for earnings calls, conferences, investor meetings, and other public company calls for over 18,000 public companies globally.
Data Overview
Asset Class: Public Companies
Data Frequency: Event-driven
Delivery Frequency: Hourly
History: Data available back to 2003
Data Methodology
Alexandria's global transcripts dataset allows users to leverage valuable sentiment analysis on company transcripts, which are tagged to companies, speakers, and topics. First, Alexandria receives a streaming feed of transcripts from FactSet that have been tagged with the appropriate companies and speakers. Alexandria then parses each transcript into sections of text, which are analyzed using machine-learning algorithms to determine the topics and sentiment. These algorithms have been trained to read like a human; they observe transcripts labeled by research analysts for sentiment and topics.
As of April 2020, Alexandria covers over 250 granular topics and is consistently expanding this list to capture emerging trends. The sections of text, with their associated topics, sentiment, and metadata, are transformed into structured tables for efficient analysis.
Use Cases
Company-Level Sentiment Analysis
- Uncover company executives' positive and negative perspectives on specific topics using sentiment analysis from public company calls, which can be used to anticipate company performance.
- The transcripts dataset allows users to bypass navigating complex, dense transcript texts littered with management bias. Alexandria's machine learning algorithms are trained by financial analysts, so they account for management bias in the process of generating topic-specific sentiment scores for each section.
- By offering section-level sentiment scores, this product provides voluminous observations to power refined short-, medium-, and long-term trading strategies.
- A case study produced by Alexandria featured a long/short trading strategy that quintiled companies by net sentiment and rebalanced monthly using the S&P 500 universe. This model portfolio experienced a 9.6% annual return. Conversely, a portfolio that applied the same methodology using sentiment generated by a dictionary approach (i.e., versus Alexandria's analyst-driven machine learning approach) saw a -2.2% annual return. The case study showcases the accuracy and efficacy of their methodology.
Sector and Macro Analysis
- Identify trends in management sentiment across sectors and markets. With over 250 topics covered, users can track sentiment across specific topics and capture emerging themes as new topics are added by Alexandria.
Blend with Raw Transcripts
- Leverage sentiment indicators in Alexandria's transcripts dataset to enhance custom Natural Language Processing (NLP) analysis performed on raw transcripts. This product is often used alongside in-house transcript analysis; it can also be integrated to improve the accuracy of sentiment models.
- The transcripts dataset is built on FactSet's XML Transcript product, making it easy to annotate raw transcripts and expedite analysis.
The details provided above are as of April 2020.
If you have any questions or would like to learn more about any of the content mentioned above, please contact us at sales@factset.com.
Please visit the product page on the Open:FactSet Marketplace for more information: Alexandria Transcript Text Analytics.



